HBase简介及其在存储支持服务中的应用
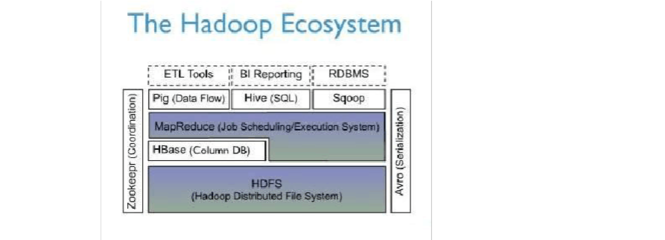
HBase是一种基于Hadoop的分布式、可伸缩的列式数据库,它设计用于处理海量结构化数据,是大数据生态系统中关键的存储组件之一。作为Apache软件基金会的顶级项目,HBase以其高可靠性、高性能和强一致性著称,尤其适用于需要随机、实时读写访问超大规模数据集的场景。
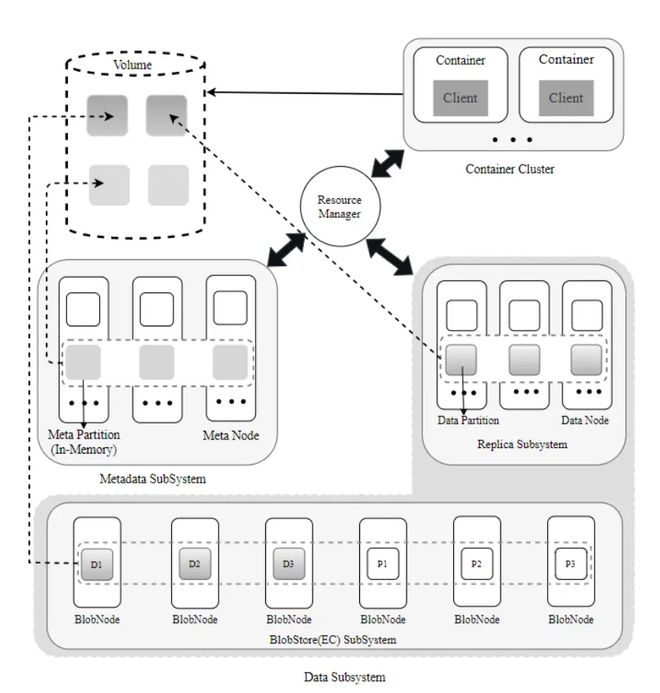
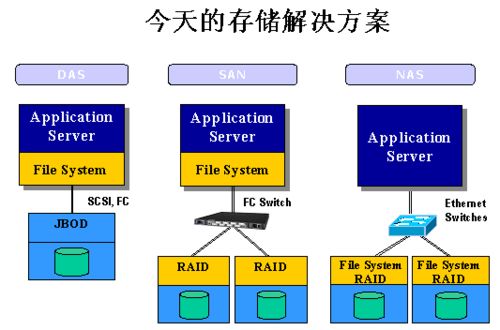
从架构上看,HBase构建在Hadoop分布式文件系统(HDFS)之上,利用HDFS提供的高容错性和底层存储支持。其数据模型类似于Google的Bigtable,将数据组织成表的形式,表由行和列组成,列进一步划分为列族。这种灵活的模型允许稀疏存储,非常适合半结构化或非结构化数据。
在存储支持服务方面,HBase扮演着至关重要的角色:
- 海量数据存储:HBase能够轻松存储PB级别的数据,通过区域分割和负载均衡机制,实现数据的水平扩展。
- 实时读写服务:与传统的批处理系统不同,HBase支持低延迟的随机读写操作,使其成为实时应用程序的理想后端存储。
- 高可用性与容错:通过主从架构和数据的多副本机制,HBase确保即使部分节点失效,系统仍能持续提供服务。
- 强一致性保证:HBase提供行级原子性,确保对同一行的所有读写操作都是一致的。
- 灵活的数据模型:动态添加列的能力使其能够适应不断变化的数据模式,为多样化的业务场景提供支持。
- 与Hadoop生态集成:HBase可以无缝与MapReduce、Spark等计算框架集成,形成完整的数据处理流水线。
典型应用场景包括用户行为日志存储、实时消息系统、推荐引擎的数据存储等。随着企业对实时数据处理需求的增长,HBase作为高性能的存储支持服务,在大数据解决方案中的地位日益巩固。
HBase也有其局限性,例如对复杂查询的支持相对较弱,通常需要与搜索索引或分析型数据库配合使用。但在需要高吞吐量、低延迟访问大规模数据的场景下,HBase仍然是无可替代的选择。
如若转载,请注明出处:http://www.wsooxw.com/product/92.html
更新时间:2026-06-19 12:19:47