为何选择 Databricks 而非 Snowflake 聚焦存储支持服务的深度考量
在企业构建现代数据架构时,Databricks 与 Snowflake 都是备受瞩目的顶尖平台。尽管两者都提供了强大的云数据能力,但在存储支持服务方面,Databricks 展现出的独特优势,往往成为我们选型的关键因素。以下是基于存储支持服务维度的核心分析。
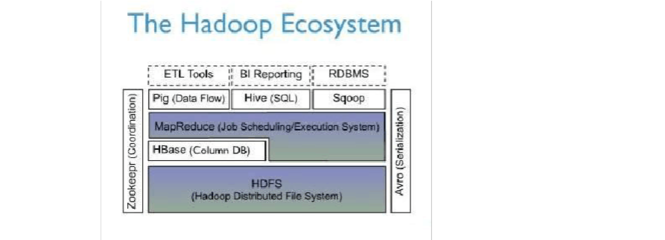
1. 开放性与灵活性:Lakehouse 架构的基石
Databricks 的核心优势在于其倡导并实现的 Lakehouse(湖仓一体) 架构。该架构的存储层完全建立在开放的云对象存储(如 AWS S3、Azure Blob Storage、Google Cloud Storage)之上。这意味着:
数据所有权与控制权:企业始终完全拥有并控制底层数据文件,避免了供应商锁定的风险。数据可以跨多种工具和引擎直接访问。
成本效益:直接使用云厂商的对象存储,通常比专用存储格式成本更低,且便于利用云存储的生命周期管理策略进一步优化成本。
* 格式开放性:原生支持 Delta Lake(一种开放格式),实现了事务性、版本控制、时间旅行等功能,同时保持了与 Parquet、JSON 等广泛生态的兼容。
相比之下,Snowflake 虽然管理简单,但其底层存储是专有、封闭的,数据必须通过 Snowflake 的服务进行导入和访问,在灵活性和数据可移植性上存在局限。
2. 统一的数据处理与 AI 工作负载支持
Databricks 的存储层与计算引擎深度集成,专为复杂的 ETL、数据科学和机器学习 工作流设计。
统一平台:同一平台内可无缝衔接数据提取、批流处理、高级分析和模型训练。存储层直接支持这些多样化的计算范式,减少了数据在不同系统间移动的延迟与复杂度。
对非结构化数据的友好性:开放的存储架构使其能够轻松处理和分析图像、文本、日志等非结构化数据,这些数据可直接存储在对象存储中,供 Databricks 上的多种计算框架(如 Spark、MLflow)使用。这对于构建 AI/ML 应用至关重要。
Snowflake 作为卓越的云数据仓库,在结构化数据的 SQL 分析方面性能领先,但其存储层对支持数据工程和数据科学全流程的原生能力相对较弱,通常需要与其他工具(如 Snowpark 扩展)配合,且对非结构化数据的处理不如前者直接和灵活。
3. 精细化的治理与性能优化
Databricks 通过其 Unity Catalog 统一治理层,在开放的存储之上提供了企业级的治理能力。
统一治理:跨工作区和云存储,对数据、AI 资产(如模型、特征)进行集中的元数据管理、访问控制和血缘追踪。治理策略直接作用于底层数据文件。
存储层智能优化:Delta Lake 格式自带的事务日志、小文件合并、数据压缩与索引(如 Z-Ordering)等功能,直接在存储层优化了数据布局,显著提升了大规模数据查询的性能。
Snowflake 在数据治理和自动化管理(如自动聚类)方面同样出色,但其优化完全在封闭系统内进行,对于希望在存储层实施更定制化优化策略的团队而言,灵活性稍逊。
###
选择 Databricks 而非 Snowflake,在存储支持服务层面,本质上是选择 开放、灵活的统一数据平台 与 专为高性能分析优化的封闭式数据仓库 之间的路径。
如果您的核心诉求是:
避免供应商锁定,保持数据主权和可移植性。
构建一个支持从 ETL 到 BI 再到 AI 的端到端数据与 AI 平台。
需要直接、灵活地处理结构化与非结构化数据。
希望在开放的云存储上实施精细化的治理与性能优化。
Databricks 基于开放存储的 Lakehouse 架构提供了更坚实的基础和更长远的技术战略优势。反之,如果您的场景极度聚焦于高性能的集中式 SQL 分析,且追求极致的易用性和管理自动化,Snowflake 则是优秀的选择。这一选型应紧密结合企业自身的数据战略、团队技能栈和长期业务目标。
如若转载,请注明出处:http://www.wsooxw.com/product/67.html
更新时间:2026-06-19 23:33:26